Nagios es una herramienta de monitorización muy buena y extendida. Mediante scripts consulta los parámetros de las máquinas y en función de los límites definidos manda alertas por correo o SMS.
Pero, ¿y los valores de ayer? Un histórico de los datos es casi imprescindible en la monitorización. Pues también es posible, aunque no viene configurado por defecto. Esto lo hace nagios a partir de un dato que devuelven los scripts llamado "performance data". Este campo proporciona el valor del parámetro que se ha leído y se añade al campo básico, que devuelve un valor entre 0 y 3 para saber el estado del parámetro. Una vez que nagios tiene estos valores, mediante un script que se ejecuta periódicamente, lo va metiendo en una RRD (Round Robin Database). Finalmente, un software de terceros genera las gráficas a partir de estas RRD.
Hay varios programas que realizan esta tarea, como pnp4nagios, check_mk, nagiosgraph, ... Por otro lado está cacti, que es un caso especial. Cacti es por si mismo un sistema de monitorización. Tiene sus scripts, alimenta sus RRD y genera sus gráficos. Como ventaja tiene que la generación de gráficos es totalmente personalizable y como desventaja que no genera alertas en función de los valores de los parámetros. Y aquí es donde viene la pregunta: ¿se puede utilizar cacti sólo para la parte de gráficos, dejando a nagios la adquisición de datos?
Hay varia maneras de realizar está integración:
- Por separado. Realmente no se integran, cada uno ejecuta sus scripts. Los dos sistemas son independientes. Todo el trabajo de consultar los parámetros se duplica.
- Cacti consulta. Este se encarga de ejecutar los scripts y alimentar sus RRD. Después nagios consulta el último valor de la RRD y genera el estado (y alarma en su caso) del parámetro.
- Nagios consulta. Este se encarga de ejecutar los scripts. Como ventaja tiene que los scripts se pueden ejecutar con los agentes NRPE o NCSA. Después cacti consulta a nagios y crea su propia RRD.
- Parecido al paso 3. Pero nagios aprovecha para crear su RRD. Después cacti genera la gráfica a partir de esta RRD. La diferencia es que no crea su propia RRD sino que utiliza la de nagios, siendo este quien la alimenta.
A continuación se describe este último paso.
Primero hay que configurar nagios para que genere las RRD. Esto se puede hacer con scripts de terceros, por ejemplo los de pnp4nagios. La configuración es simple y en su página web viene muy bien explicado.
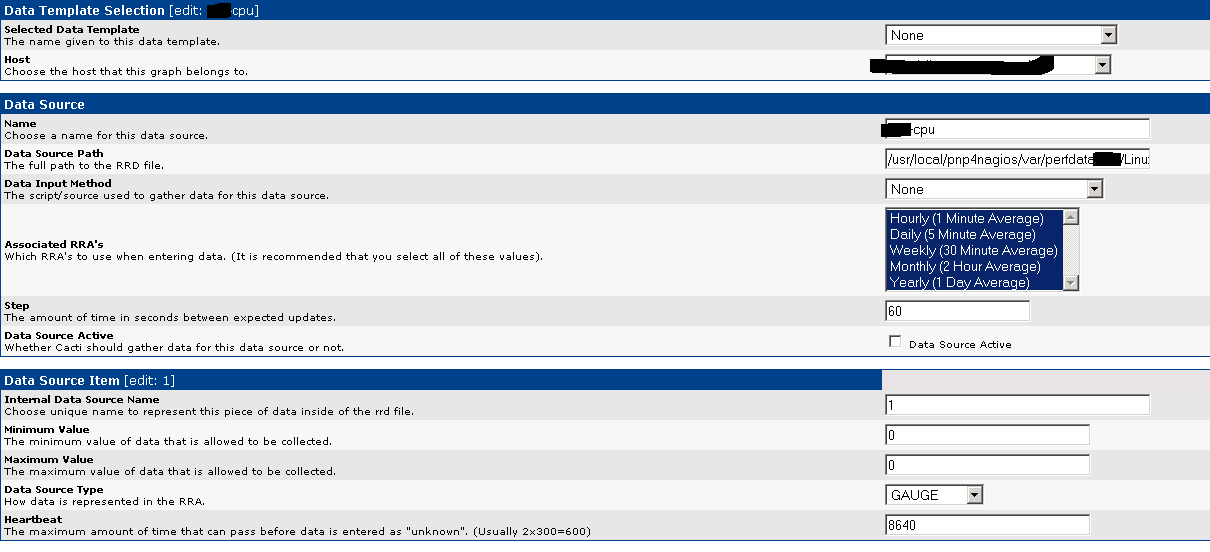
Después, hay que realizar los pasos normales para crear la gráfica en cacti, pero rellenando los campos del datasource con datos adaptados a lo que queremos.

Estos son los campos a rellenar:
- data source path: Normalmente se deja en blanco para que cacti lo cree, o se le da la ruta de un archivo inexistente. En este caso se le da la ruta de la RRD que ha creado nagios.
- data input method: None. Cacti no va a alimentar esta RRD.
- associated rra's: Seleccionados todos.
- data source active: no seleccionado. Cacti no va a alimentar esta RRD.
El resto de campos (step y los de data source item) hay que rellenarlos con la información específica de la RRD. Para conocer esta información, hay que ir a la máquina donde está instalado nagios y ejecutar el comando rrdinfo, que muestra los parámetros de configuración de la RRD.
[root@XXX~]# rrdtool info /usr/local/pnp4nagios/var/perfdata/XXX/Linux-CPU.rrd
filename = "/usr/local/pnp4nagios/var/perfdata/XXX/Linux-CPU.rrd"
rrd_version = "0003"
step = 60
last_update = 1304006344
header_size = 5044
ds[1].index = 0
ds[1].type = "GAUGE"
ds[1].minimal_heartbeat = 8640
ds[1].min = NaN
ds[1].max = NaN
ds[1].last_ds = "0.000"
ds[1].value = 0,0000000000e+00
ds[1].unknown_sec = 0
ds[2].index = 1
ds[2].type = "GAUGE"
ds[2].minimal_heartbeat = 8640
ds[2].min = NaN
ds[2].max = NaN
ds[2].last_ds = "0.000"
ds[2].value = 0,0000000000e+00
ds[2].unknown_sec = 0
ds[3].index = 2
ds[3].type = "GAUGE"
ds[3].minimal_heartbeat = 8640
ds[3].min = NaN
ds[3].max = NaN
ds[3].last_ds = "0.000"
ds[3].value = 0,0000000000e+00
ds[3].unknown_sec = 0
En este ejemplo se ve una RRD con 3 datasource configurados. Los nombres de los datasources están entre corchetes. No hay que confundir este valor con algún tipo de ID numérico. Este se corresponde en cacti con
internal data source name.
Los demás campos (step, min, max, heartbeat, type) son fáciles de identificar.
Una vez configurado el data source, el proceso para la generación del gráfico es el normal, que se puede encontrar en la documentación de cacti.